Er is weer een nieuwe update! Google ondersteunt niet langer de noindex richtlijn in een robots.txt bestand. Google is nog wel zo aardig om ons hiervan op de hoogte te stellen. Ze sturen momenteel een bericht naar je Google Search Console inbox met de volgende melding:

Wat is een robots.txt-bestand? Het laat crawlers van zoekmachines weten welke bestanden of pagina’s de crawler niet of wél kan aanvragen op je website. Op deze manier voorkom je dat je site wordt overspoeld met verzoeken. Je kon tot nu toe gebruik maken van de noindex-richtlijn om een pagina niet op Google weer te geven, maar dat gaat snel veranderen! Als je het bericht opent, zie je het volgende:
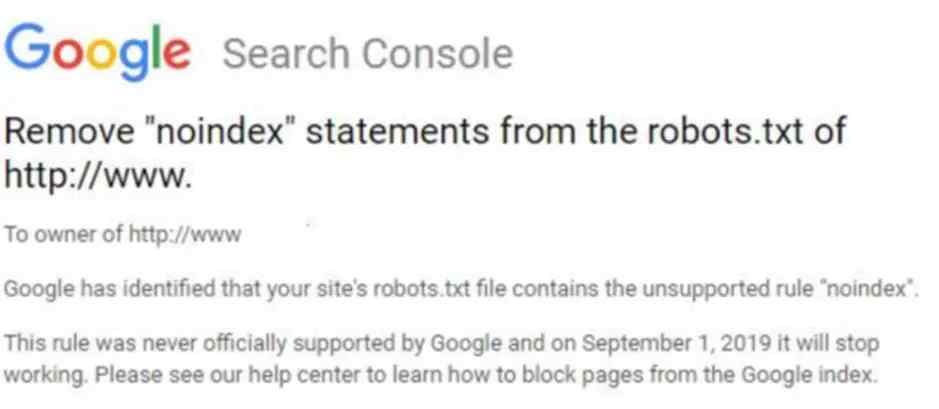
De noindex-richtlijn wordt niet langer ondersteund
Tot op heden heeft Google de robots.txt richtlijn ondersteund, maar vanaf 1 september 2019 zal dat niet langer het geval zijn. Ze hebben het tot nu toe altijd toegestaan, omdat het wereldwijd werd gebruikt door website eigenaren, maar het is geen officiële richtlijn van Google.
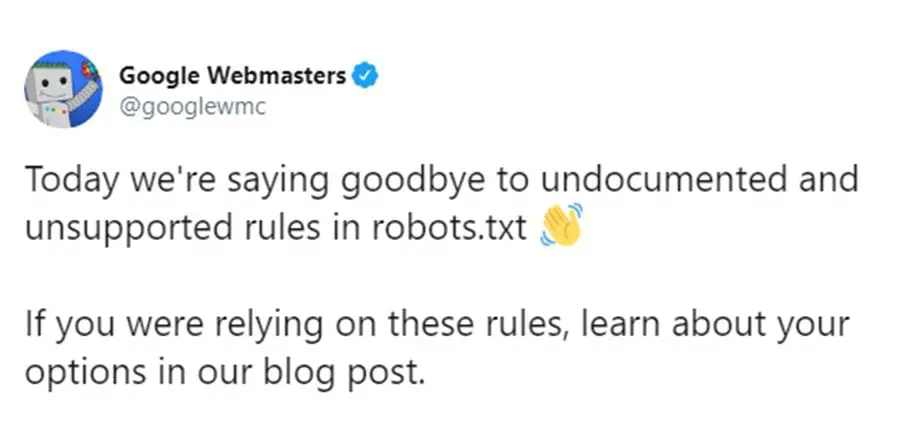
Google heeft een officiële tweet verstuurd waarbij ze het volgende aangeven: vandaag nemen we afscheid van niet-ondersteunende en niet-gedocumenteerde regels in robots.txt.
Wat zijn alternatieve opties?
Ben je afhankelijk van de no-index richtlijn in je robots.txt bestand? Dan heb je tot 1 september 2019 de tijd om een alternatief te gebruiken. Google heeft 5 alternatieven opgesomd:
- Wachtwoord beveiliging: tenzij mark-up wordt gebruikt om abonnements- of paywalled-inhoud aan te geven, zal het verbergen van een pagina achter een login meestal verwijderd worden uit de Google index. Bij een paywall krijg je digitaal toegang tot informatie nadat je structureel of eenmalig (met een abonnement) geld betaald hebt. Je kunt bijvoorbeeld een inleiding of voorvertoning lezen, maar je moet betalen om het gehele document of artikel te lezen. Kranten zoals The New York Times en The Wall Street Journal maken hier gebruik van.
- Noindex in robots meta tags: als crawlen is toegestaan, is dit de meest effectieve manier om URL’s uit de index te verwijderen. Het is een vaak gebruikte waarde die je kunt toevoegen aan de HMTL-broncode van een webpagina. Met deze waarde stel je aan Google voor om de webpagina niet in de lijst met zoekresultaten op te nemen.
- 410 en 404 http- status codes: beide codes betekenen dat de pagina niet bestaat, waardoor URL’s uit de index van Google worden verwijderd zodra ze zijn gecrawld en verwerkt.
- Disallow in robots.txt: de zoekmachine kan een pagina indexeren die ze kennen. Wanneer je een pagina blokkeert voorkom je dat de pagina wordt gecrawld en dus niet wordt geïndexeerd. Deze optie raden we echter niet aan, omdat je niet 100% zeker bent dat de pagina niet wordt geïndexeerd.
- Remove URL-tool in search console: deze tool is een eenvoudige en snelle methode om een URL tijdelijk uit de zoekresultaten van Google te verwijderen.
Als je de melding in Google Search Console ontvangt, dan is het belangrijk om ervoor te zorgen dat je de noindex-richtlijn niet meer gebruikt en één van de alternatieven gebruikt voor 1 september 2019. Wij checken dit voor al onze klanten en we voorzien je van het juiste advies.


